مقیاسدهی اپلیکیشنهای ابری و توزیعشده چگونه است؟
calendar_today
Dec 20, 2025
schedule
1 دقیقه مطالعه

نکات کلیدی
- برای مقیاس غیرقابلپیشبینی طراحی کنید: جهشهای ترافیکی تا ده برابر را با ظرفیت رزروشده و مدارشکنها مدیریت کنید.
- زیرساخت را بر اساس میزان حیاتیبودن طبقهبندی کنید و تلاشها را هوشمندانه متمرکز کنید، چون همه چیز به صددرصد دسترسپذیری نیاز ندارد.
- همه چیز را خودکار کنید: سیستمهای خودترمیم بسازید که قبل از دخالت انسان بازیابی شوند.
- عملکرد را در همه لایهها بهینه کنید: رایانش لبه، شکلدهی ترافیک و شبکههای تحویل محتوا (CDN) برای سرعت.
- شعاع انفجار را مهار کنید: معماری چندمنطقهای که خرابیها را به درصد کمی از کاربران محدود میکند.
اهداف
مهاجرت ابری ما روی سه هدف اصلی متمرکز بود: مقیاسدهی به شکل مقرونبهصرفه و کارآمد، دستیابی به تابآوری بالا که برای مؤسسات مالی اهمیت ویژهای دارد، و ارائه عملکرد قوی تا کندی سیستمها کاربران را به سرویسهای جایگزین سوق ندهد.مقیاسدهی کارآمد
برای رسیدن به کارایی باید الگوهای استفاده و رفتار مشتری تحلیل شود. سازمانها باید قابلیتهای پیشبینی را توسعه دهند و در عین حال با مقیاسدهی کشسان، انعطافپذیری را حفظ کنند. شکلدهی ترافیک روشی ارائه میدهد برای شناسایی قابلیتهای پرتکرار، تا مقیاسدهی هدفمند روی اپلیکیشنهای حیاتی انجام شود. مدیریت ظرفیت کلی هم یک عنصر حیاتی دیگر است. صرفاً اضافه کردن سرور تضمینکننده موفقیت نیست. مصالحههایی با هزینه وجود دارد و نیازمند بررسی دقیق است.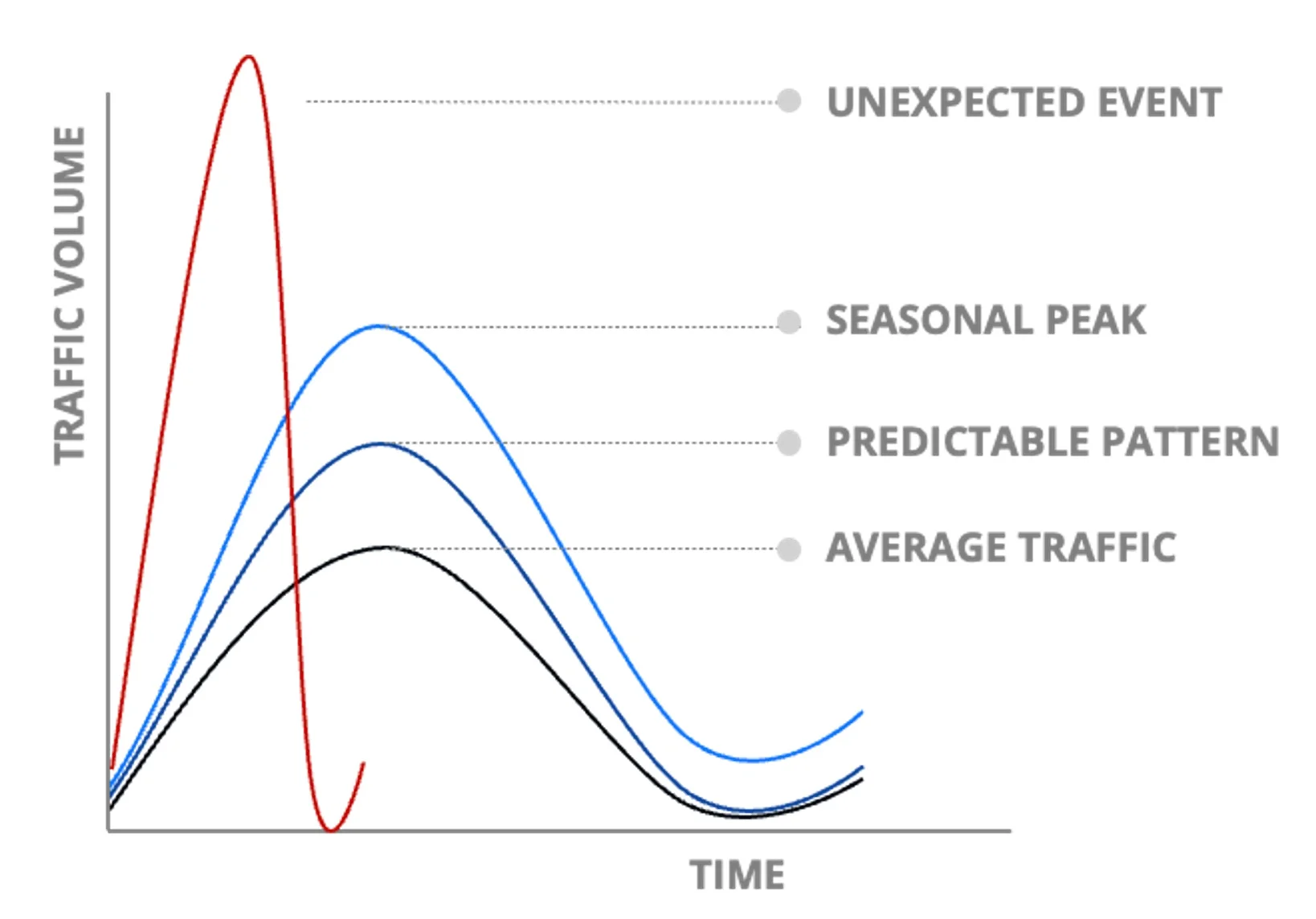
الگوهای ترافیک و اندازهگذاری
الگوهای ترافیک بنیان مقیاسدهی کارآمد هستند. ترافیک متوسط، خط پایهای است که سیستمها بهطور منظم مدیریت میکنند. الگوهای قابل پیشبینی وجود دارد که توسط رویدادهای تکرارشونده مثل واریز حقوق ایجاد میشود و مشتریان را به بررسی موجودی حساب ترغیب میکند. اوجهای فصلی هم در طول سال رخ میدهد و نیازمند برنامهریزی پیشدستانه است. رویدادهای غیرمنتظره چالش متفاوتی ایجاد میکنند. حملات DDoS بهطور مکرر رخ میدهند و ترافیک میتواند بیش از ده برابر بار عادی یا حتی بیشتر شود. مهاجمان از همان منابع ابری استفاده میکنند که کاربران واقعی هم به آن دسترسی دارند. سازمانها باید همزمان این حملات را مسدود کنند و در عین حال توافقنامههای سطح خدمت برای مشتریان واقعی که تراکنشهای واقعی انجام میدهند را حفظ کنند. اندازهگذاری درست بر اساس الگوهای تثبیتشده به جلوگیری از مشکلات عملیاتی کمک میکند. با این حال، مقیاسدهی کشسان محدودیتهایی دارد؛ در طول فرایند مقیاسدهی، اپلیکیشنها باید بالا بیایند و اتصال به سرویسها و دیتابیسها را برقرار کنند. برقرار کردن اتصال زمان میبرد. تا زمانی که اینستنسها به آمادگی عملیاتی برسند، ممکن است چند دقیقه گذشته باشد. وقتی حجمهای بزرگ در حین راهاندازی همزمان اینستنسها وارد میشوند، رقابت (contention) در سراسر سیستم شکل میگیرد. بهجای تکیه صرف بر مقیاسدهی کشسان، باید تصویر کامل عملیاتی را در نظر گرفت، از جمله الگوها و عوامل مرتبط. ظرفیت محاسباتی رزروشده این چالشها را پوشش میدهد. منابع رزروشده دسترسپذیری را در زمان نیاز تضمین میکنند، بهخصوص وقتی رقابت در میان سازمانهای دیگر که از استخرهای سرویس اشتراکی استفاده میکنند وجود دارد. محاسبات رزروشده همچنین صرفهجویی هزینه ایجاد میکند. مدیریت هزینه نیازمند توجه مستمر است. فرایندهای FinOps باید بهصورت منظم، در بازههای ماهانه یا هفتگی، اجرا شوند نه فقط گاهی اوقات.مقیاسدهی فراتر از اضافه کردن سرور
مقیاسدهی فقط اضافه کردن سرور نیست. وقتی مقیاسدهی رخ میدهد، پرسش بنیادی این است که آیا اپلیکیشن واقعاً به خاطر تقاضای واقعی مشتری نیاز به مقیاسدهی دارد یا اینکه سرویسهای بالادستی بهخاطر صفبندی پاسخگو نیستند و سرعت پاسخ سیستم را کم کردهاند. وقتی تردها منتظر پاسخ میمانند و نمیتوانند اجرا شوند، فشار روی CPU و حافظه زیاد میشود و مقیاسدهی کشسان فعال میشود، حتی در حالی که تقاضای واقعی افزایش پیدا نکرده است. این سناریو نیازمند طراحی برای شکست و ادغام آن با راهبردهای مقیاسدهی است. مدارشکنها (circuit breakers) اینجا سازوکار حیاتیاند. وقتی سرویسهای بالادستی کند میشوند یا از کار میافتند، مدارشکنها اجازه نمیدهند اپلیکیشن بینهایت منتظر پاسخ بماند. در عوض، حدّ زمانانتظار را اعمال میکنند تا سیستم یا در بازه تعریفشده پاسخ موفق بگیرد یا سریع شکست بخورد و جلو برود. این طراحی از فرسودگی تردها جلوگیری میکند، مصرف منابع غیرضروری را کاهش میدهد و جلوی تریگرهای غلط مقیاسدهی را میگیرد. بدون مدارشکن، وابستگیهای کند میتوانند به افت عملکرد سراسری تبدیل شوند و باعث شوند مقیاسدهی کشسان سرورهای بیشتری اضافه کند که مشکل وابستگی را حل نمیکنند.تابآوری بسیار بالا
تابآوری یعنی آمادهبودن برای شکستهای اجتنابناپذیر سیستم. کشف زودهنگام و آمادگی برای اجرای فرایندهای failover حیاتی است. با این حال، دستیابی به صددرصد دسترسپذیری برای همه مؤلفهها نه عملی است و نه ضروری. زیرساخت را میتوان بر اساس میزان حیاتیبودن به چهار سطح تقسیم کرد. مؤلفههایی که «حیاتی» شناخته میشوند باید دسترسپذیریشان تا حد ممکن نزدیک به صددرصد باشد. DNS نمونه این دسته است؛ هرچقدر یک سایت خوب طراحی شده باشد، خرابی DNS مانع دسترسی کامل میشود. سطح «قابل مدیریت» شامل مؤلفههایی است که failover اجازه میدهد در صورت شکست، عملیات ادامه پیدا کند. این اجازه میدهد هدفگذاری «چهار نُه» دسترسپذیری (۹۹.۹۹ درصد) انجام شود که معادل حدود ۵۲ دقیقه قطعی قابل قبول در سال است. سطح «قابل تحمل» مؤلفههایی را دربر میگیرد که تابآوری درونساخت دارند. سرویسهای توکن که داده را برای دورههای طولانی کش میکنند نمونه این دستهاند. اگر سرویس در بازه اعتبار کش از دسترس خارج شود، عملیات با داده کششده ادامه پیدا میکند. در نهایت، سطح «قابل قبول» شامل مؤلفههایی است که از دست رفتن محدود داده در آن قابل پذیرش است، مثل برخی سیستمهای لاگ. شدت اثر، اهداف تابآوری را تعیین میکند.عملکرد
عملکرد هم روی تجربه کاربر اثر جدی دارد و هم روی هزینههای زیرساخت. همه اپلیکیشنها یکسان عمل نمیکنند. «نقطه حضور» میتواند برای تجربه بهتر مشتری استفاده شود، چون لگ روی وبسایتها بهشدت آزاردهنده است، بهخصوص روی موبایل. سرعت اهمیت زیادی دارد چون اعتماد میسازد؛ کاربران تجربه بهتر و سریعتر میخواهند. موتورهای جستجو مثل Google هم این اهمیت را با وارد کردن سرعت در الگوریتمهای رتبهبندی نشان دادهاند. عملکرد موبایل وقتی پای اتصال شبکه وسط است حتی حیاتیتر میشود. از منظر زیرساختی هم وقتی مشتریان برای رسیدن به همان هدف زمان کمتری روی زیرساخت صرف میکنند، هزینه عملیاتی کاهش مییابد. بهکارگیری راهبردهای جامع عملکرد، از شروع پیادهسازی تا استقرار کامل این رویکردهای معماری، باعث کاهش ۷۱ درصدی تأخیر (latency) شد. این راهبردها قابل تطبیق با زمینههای کسبوکار دیگر هم هستند.قدرت پنج: راهبردهای کلیدی
پنج حوزه تمرکز رویکرد معماری را هدایت میکند: استقرار چندمنطقهای، بهینهسازی عملکرد بالا، خودکارسازی جامع، مشاهدهپذیری همراه با خودترمیم، و امنیت مستحکم.چندمنطقهای
معماری چندمنطقهای ایزولیشن و بخشبندی ایجاد میکند تا جداسازی کارکردی ممکن شود. این رویکرد مدیریت خرابیهای منطقه، خرابیهای زون و خرابیهای شبکه را تسهیل میکند و در عین حال شعاع انفجار را محدود میسازد. با پایگاه مشتری ۹۴ میلیون نفری، خرابیهای سطح زون میتواند طوری محدود شود که فقط درصد کمی از کاربران آسیب ببینند، نه کل جمعیت. پیادهسازی چندمنطقهای نیازمند رسیدگی به مدیریت DNS است، چون مناطق مختلف لودبالانسرهای جداگانه دارند و هماهنگی لازم است. باید مدیریت ترافیک بین مناطق تعیین شود. در داخل مناطق که چندین زون دارند، گزینههایی برای توزیع ترافیک وجود دارد.خرابیهای زونی
سناریویی را در نظر بگیرید که یک لودبالانسر ترافیک را بین دو زون در یک منطقه توزیع میکند. هر اپلیکیشن وضعیت سالم گزارش میدهد و زونها هم سالم به نظر میرسند، بنابراین ترافیک به هر دو زون ادامه دارد. اما اگر یک اپلیکیشن در یکی از زونها با سیستمهای بکاند مشکل اتصال داشته باشد و زون دیگر طبیعی کار کند، ترافیک همچنان به زون آسیبدیده میرسد. اگر اپلیکیشن probeهای آمادگی (readiness) و زندهبودن (liveness) را پیاده کند اما وضعیت وابستگیهای سیستم را وارد health check نکند، مشکل ایجاد میشود. بدون سازوکار بازخورد مناسب، لودبالانسر همچنان ترافیک را مسیردهی میکند و به شکست اپلیکیشن منجر میشود.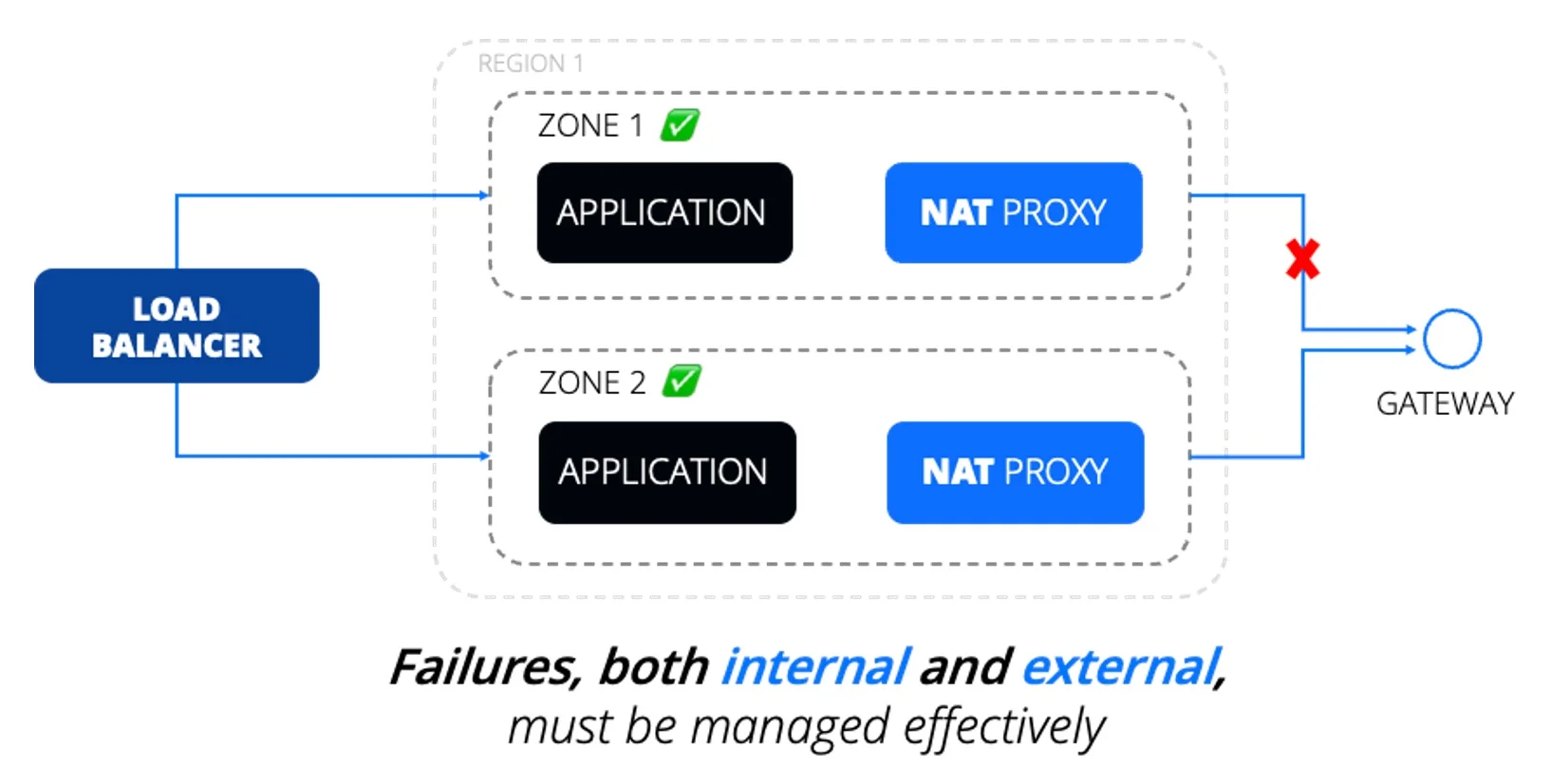 حل مسئله یا نیازمند این است که اطلاعات سلامت وابستگیها از طریق readiness و liveness probeها به لودبالانسر منتقل شود، یا مسیردهی مجدد مبتنی بر پروکسی به زونهای سالم پیاده شود. هم خرابیهای داخلی و هم خارجی باید بهطور مؤثر مدیریت شوند تا قطعی اپلیکیشن برطرف شود.
حل مسئله یا نیازمند این است که اطلاعات سلامت وابستگیها از طریق readiness و liveness probeها به لودبالانسر منتقل شود، یا مسیردهی مجدد مبتنی بر پروکسی به زونهای سالم پیاده شود. هم خرابیهای داخلی و هم خارجی باید بهطور مؤثر مدیریت شوند تا قطعی اپلیکیشن برطرف شود.
خرابیهای منطقهای
در استقرار چندمنطقهای، ما به یک «پالسچک» منطقهای واحد و یکنواخت تکیه میکنیم که هر ۱۰ ثانیه اجرا میشود تا دید یکنواخت و بهموقع از سلامت مناطق فراهم شود. تصمیمهای حیاتی شامل این است که آیا خرابیها نیازمند failover کامل به مناطق جایگزین هستند یا سرویسِ افتکرده (degraded) هنوز قابل قبول است. قابل قبول بودن سرویس افتکرده به بخشبندی اپلیکیشن بستگی دارد. اگر سرویسهای حیاتی از کار بیفتند، failover ممکن است لازم باشد (مثلاً وقتی صفحه فرود داشبورد از کار افتاده). اگر عناصر کماهمیتتر شکست بخورند، اپلیکیشن میتواند برای جلوگیری از اثر گسترده به کار ادامه دهد. failover اثر «گله شتابان» ایجاد میکند (مثلاً وقتی یک منطقه کامل از کار میافتد، موج ناگهانی ترافیک هدایتشده میتواند مناطق باقیمانده را تحت فشار قرار دهد و auto-scaling برای فراهم کردن ظرفیت اضافی زمان نیاز دارد) و مشکلات دیگری ناشی از بازتوزیع ترافیک ایجاد میشود. معیارهای health check، از جمله آستانههای شکست و موفقیت برای بررسی سلامت اپلیکیشن، پاسخ مناسب را تعیین میکنند.چالشهای چندمنطقهای
تکثیر داده بین مناطق و تضمین سازگاری داده نگرانیهای اصلی هستند. شارد کردن مشتریان یک رویکرد است وقتی دیتاسنترها در چند مکان محدودند اما مشتریان در سراسر کشور توزیع شدهاند. شارد کردن مشتریان و سرویسدهی از مکانهای نزدیکتر جغرافیایی میتواند نیازهای تکثیر را پوشش دهد، شاید حتی از تکثیر جلوگیری کند و معماری را سادهتر کند. مدیریت state نیازمند تصمیمهای راهبردی است. مدیریت state برای حفظ وابستگی نشست (session affinity) برای نشستهای فعال، همراه با امکان failover در صورت نیاز، به عملیات مؤثر کمک میکند.عملکرد بالا
عملکرد بالا برای تجربه کاربر ضروری است. عملکرد خوب را میتوان با یک بوق آزاد مطمئن مقایسه کرد؛ کاربران انتظار پاسخ فوری بدون تأخیر دارند. رایانش لبه یک روش اصلی برای رسیدن به اهداف عملکرد است. وبسایتهای مدرن با رابطهای کاربری پیچیده، محتوای سنگینی دارند. محتوا میتواند به نقاط حضور (PoP) نزدیک به مشتری منتقل شود، در حالی که سرورهای مبدا فقط عملیات پویا و سرویسهای حیاتی را انجام دهند: ورود، حسابها و پرداختها.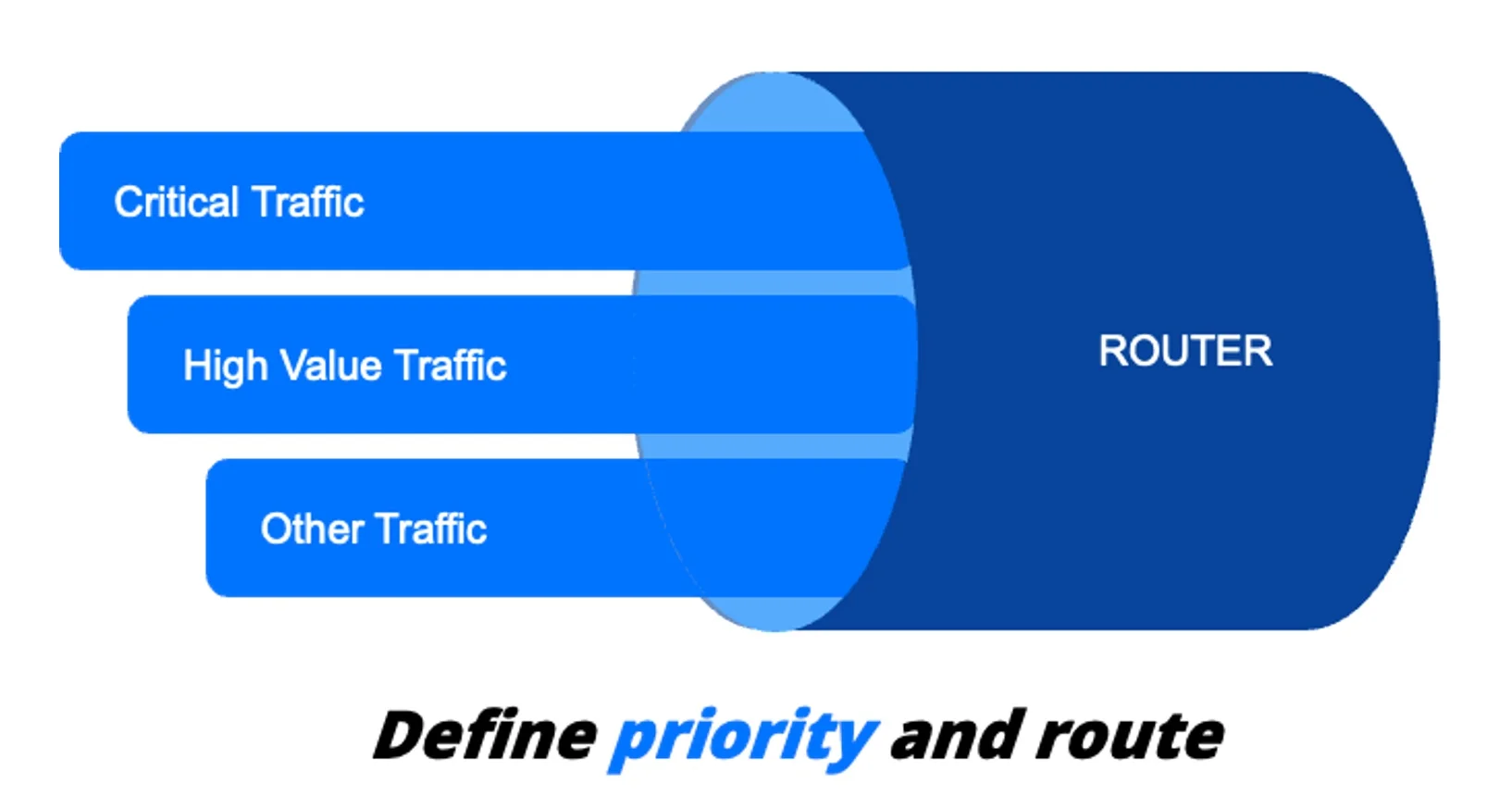 شکلدهی ترافیک اجازه میدهد ترافیک دستهبندی شود. ترافیک حیاتی شامل کارکردهای ضروری برای عملیات کسبوکار است: فعالیتهای روزانه مشتری مثل ورود، بررسی موجودی و پرداختها. منابع تخصیصیافته به سرویسهای حیاتی باید همیشه عملیاتی بمانند. حتی اگر ترافیک دیگر در شرایط فشار افت کیفیت پیدا کند، ممکن است قابل قبول باشد.
شکلدهی ترافیک اجازه میدهد ترافیک دستهبندی شود. ترافیک حیاتی شامل کارکردهای ضروری برای عملیات کسبوکار است: فعالیتهای روزانه مشتری مثل ورود، بررسی موجودی و پرداختها. منابع تخصیصیافته به سرویسهای حیاتی باید همیشه عملیاتی بمانند. حتی اگر ترافیک دیگر در شرایط فشار افت کیفیت پیدا کند، ممکن است قابل قبول باشد.
تحویل محتوا
توزیع جغرافیایی بهشدت روی عملکرد اثر میگذارد. اگر دانلود داراییها برای هر درخواست نیازمند پیمودن فاصلههای طولانی باشد، محدودیتهای فیزیکی شبکه تأخیر قابل توجه ایجاد میکند. وقتی محتوای یکسان در PoPها با منابع کششده موجود است، بازیابی در کمتر از ۱۰۰ میلیثانیه رخ میدهد، نه زمان پاسخ طولانیتر (مثلاً بیش از ۵۰۰ms) که برای دسترسی به سرور مبدا لازم است. مزایای امنیتی هم همراه بهبود عملکرد میآید، چون ترافیک مخرب میتواند در لبه مسدود شود. اتصال «آخرین مایل» هم نیازمند توجه است. عملیات اینترنت شامل چندین پرش شبکه بین دو سر است. رایانش لبه این پویایی را از مکان کاربر تا مکان لبه تغییر میدهد، معمولاً با یک پرش شبکه، و سپس شبکههای بهینهسازیشده که کارآمدتر از اتصالهای استاندارد ISP به ISP عمل میکنند. اپلیکیشنهای موبایل هم فرصتهای بهینهسازی دارند. اپهای موبایل فضای ذخیرهسازی در اختیار دارند که میتوان منابع را در آن کش کرد، از جمله resolutionهای شبکه، تنظیمات پیکربندی و محتوای پیشواکشیشده.خودکارسازی
خودکارسازی یک عنصر راهبردی حیاتی است. خودکارسازی جامع در کل پایپلاین و در هر مرحله، مزایای قابل توجهی دارد: استقرار، فراهمسازی زیرساخت، فراهمسازی محیط، health checkهای متصل به اقدامهای خودکار، و مدیریت کلی ترافیک.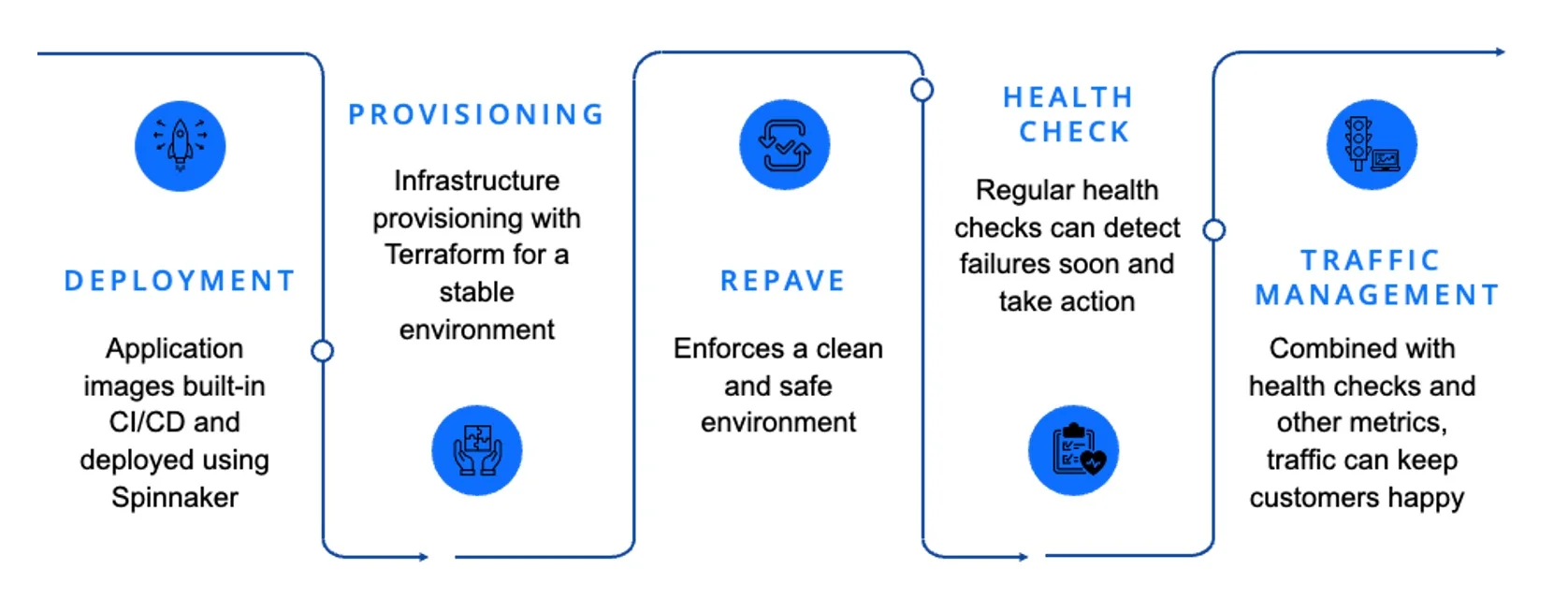 معماری نباید فقط در حد مستندسازی بماند. ساختن قالبهای معماری دارای نظر (opinionated) به تیمها کمک میکند اپلیکیشنهایی بسازند که بهطور خودکار استانداردهای معماری را به ارث ببرند. اپلیکیشنها با تعریفهای مبتنی بر manifest بهصورت خودکار مستقر میشوند، تا تیمها روی کارکردهای کسبوکار تمرکز کنند نه پیچیدگیهای ابزارهای زیرساخت.
معماری نباید فقط در حد مستندسازی بماند. ساختن قالبهای معماری دارای نظر (opinionated) به تیمها کمک میکند اپلیکیشنهایی بسازند که بهطور خودکار استانداردهای معماری را به ارث ببرند. اپلیکیشنها با تعریفهای مبتنی بر manifest بهصورت خودکار مستقر میشوند، تا تیمها روی کارکردهای کسبوکار تمرکز کنند نه پیچیدگیهای ابزارهای زیرساخت.
بازسازی دورهای زیرساخت (Repaving)
بازسازی دورهای زیرساخت یک تمرین بسیار مؤثر است که در آن زیرساخت در هر اسپرینت بهصورت نظاممند دوباره ساخته میشود. فرایندهای خودکار، اینستنسهای در حال اجرا را بهطور منظم پاکسازی میکنند. این رویکرد امنیت را بالا میبرد چون «انحراف پیکربندی» (configuration drift) را حذف میکند. وقتی drift وجود دارد یا نیاز به اعمال پچ هست، از جمله رفع آسیبپذیریهای روز-صفر، همه بهروزرسانیها میتوانند بهصورت نظاممند اعمال شوند. دورههای عملیاتی طولانی، منابع کهنه، افت عملکرد و آسیبپذیریهای امنیتی ایجاد میکند. بازآفرینی محیطها در بازههای تعریفشده (هفتگی یا دو هفته یکبار) بهصورت خودکار انجام میشود. ترافیک بهنرمی از سیستمهای در حال اجرا برداشته میشود، محیطها دوباره ساخته میشوند و سرویسها دوباره بالا میآیند و ثبات عملیاتی ایجاد میشود. پیادهسازی repaving شامل چند مؤلفه است. اسکریپتهای خودکار چرخه عمر اینستنسهای در حال اجرا را پایش میکنند. اعتبار زمانیِ مبتنی بر زمان باعث حذف مسیر (route removal) میشود، یعنی درخواست جدید پذیرفته نمیشود اما اجازه داده میشود درخواستهای جاری تمام شوند. سپس اینستنسها خاموش میشوند، نودها پاکسازی میشوند و اینستنسهای جدید ساخته میشوند. هنگام ساخت اینستنس جدید، ایمیجهای بهروز برای آسیبپذیریهای روز-صفر یا پچهای امنیتی میتوانند مستقر شوند یا اینستنسها صرفاً بازسازی شوند. سیاستها اقدام مشخص را تعیین میکنند. همه فرایندها خودکار است و حذف ترافیک قبل از repaving انجام میشود تا هیچ اثر منفی برای مشتری ایجاد نشود.Failover خودکار
failover خودکار همراه با افت کیفیت کنترلشده نیازمند توجه به نشستهای فعال است. برای مشتریانی که پردازش در جریان دارند، مدیریت نشست با نشستهای ورودی جدید فرق میکند و نیازمند مسیردهی است. باید از حلقههای failover جلوگیری شود؛ اگر هر دو منطقه ناسالم باشند، جابهجایی مداوم بین آنها مشکل را بدتر میکند. میزان تحمل تأخیر هم بسته به سناریو فرق دارد؛ شکست سرویسهای غیرحیاتی ممکن است اجازه دهد عملیات در همان مکان ادامه پیدا کند.مشاهدهپذیری و خودترمیم
مشاهدهپذیری نیازمند پاسخ خودکار به رویدادهای مشاهدهشده است. محیطهای ابری رویدادهای زیادی در مؤلفهها تولید میکنند: رویدادهای سیستم، زیرساخت و اپلیکیشن. همه رویدادهای قابل مشاهده باید اقدام خودکار داشته باشند. خودکارسازی با مشاهدهپذیری از طریق توابع سرورلس یکپارچه میشود که با تشخیص رویداد بهصورت خودکار فعال میشوند و بر اساس معیارهای تعریفشده، سوئیچ منطقهای اجرا میکنند. مشکلات دیتابیس توابع جداگانهای برای سوئیچ دیتابیس فعال میکند. فعالیتهای نگهداری میتوانند توابعی را فعال کنند که مناطق مشخص یا شبکههای خصوصی مجازی (VPC) را مسدود کنند. این مثالها نشان میدهد اقدامهای خودکاری میتوان پیاده کرد و در عین حال ارتباط با مشاهدهپذیری را حفظ کرد. پایش داشبورد ارزش تکمیلی دارد اما نباید سازوکار پاسخ اصلی باشد.پایش سلامت (Health Check)
پایش سلامت باید در چند سطح رخ دهد. در سطح اپلیکیشن، تعیین سلامت میتواند شامل ارزیابیهای پیچیده باشد: آیا خود اپلیکیشن درست کار میکند و آیا اتصال به دیتابیسها، کشها و سیستمهای دیگر همچنان برقرار است. معیارهای پیچیده میتواند در چککننده سلامت وجود داشته باشد، اما وضعیت خروجی باید ساده باشد: یک مقدار بولی که سالم یا ناسالم بودن را نشان دهد. در داخل اپلیکیشنها، health checkهایی وجود دارد که به سطح زون منتقل میشود، جایی که همه اینستنسها را بررسی میکند. این اطلاعات به سطح VPC میرود برای ارزیابی سلامت کلی VPC، و سپس به روتر جهانی خوراک میدهد. در هر سطح، ارزیابی سلامت خودکار با استفاده از شاخصهای بولی ساده انجام میشود تا تصمیمگیری سریع باشد. این رویکرد با پیادهسازی نظاممند health checkها به خودترمیم میرسد.معیارهای تصمیمگیری
در موارد استفاده زیر، وقتی هشدارها نشان میدهد یک نود در دسترس نیست و ظرفیت آسیب دیده، ممکن است بهخاطر مشکلات ارائهدهنده لازم باشد ترافیک از VPC آسیبدیده منحرف شود. وقتی هشدارهای اپلیکیشن مشکل تأخیر را نشان میدهد و عملکرد آسیب دیده، سازمانها باید تصمیم بگیرند سرویس افتکرده را ادامه دهند یا بر اساس نیازهای کسبوکار الزامات SLA را برآورده کنند. در چنین مواردی، انتخاب ادامه سرویس افتکرده یعنی پذیرش عملکرد کندتر بهجای رفتن به زون دیگری که ممکن است همان مشکل را داشته باشد.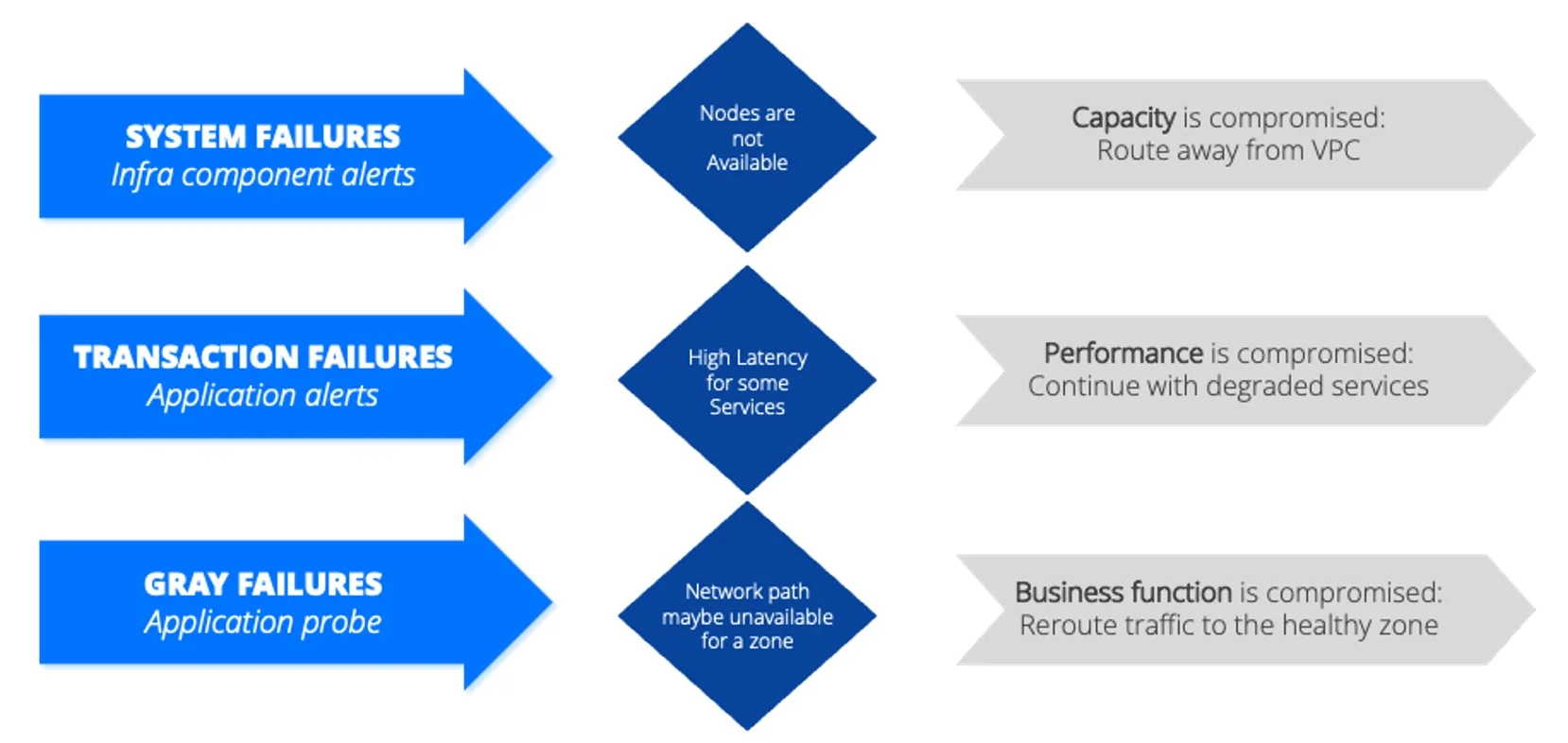 «خرابیهای خاکستری» سناریوهای مبهمی هستند که شکست قطعی نیست، اما اتصال وجود دارد. خرابیهای مرتبط با شبکه سختتر تشخیص داده میشوند. وقتی یک کارکرد کسبوکار آسیب میبیند، مسیردهی مجدد به زونهای سالم ممکن است گزینه باشد. بر اساس دادههای مشاهدهپذیری میتوان اقدامهای مختلفی اعمال کرد.
«خرابیهای خاکستری» سناریوهای مبهمی هستند که شکست قطعی نیست، اما اتصال وجود دارد. خرابیهای مرتبط با شبکه سختتر تشخیص داده میشوند. وقتی یک کارکرد کسبوکار آسیب میبیند، مسیردهی مجدد به زونهای سالم ممکن است گزینه باشد. بر اساس دادههای مشاهدهپذیری میتوان اقدامهای مختلفی اعمال کرد.
امنیت مستحکم
امنیت نیازمند پیادهسازی لایهای بر اساس مدل zero-trust است. هر لایه باید مستقل عمل کند و شکست احتمالی لایههای دیگر را مفروض بگیرد. دستگاههای کلاینت ممکن است با بدافزار آلوده شوند. امنیت پیرامونی در لبه فیلترینگ و WAF را پیاده میکند. شبکههای داخلی به بخشبندی و ایزولیشن نیاز دارند. امنیت کانتینر شامل اسکن ایمیج و اصول کمترین سطح دسترسی است. امنیت اپلیکیشن احراز هویت و مجوزدهی درست را تضمین میکند. امنیت داده رمزنگاری و کنترلهای حریم خصوصی را اعمال میکند. هر لایه دیگری را تقویت میکند.مهاجرت
دگرگونی فرهنگی برای مهاجرت موفق بنیادی است، چون عملیات ابری از اساس با سیستمهای درونسازمانی سنتی فرق دارد. ارائهدهندگان ابر دائماً سرویسها را بهروزرسانی میکنند، سیاستهای شبکه تغییر میکند، مرورگرها تغییر میکنند و عوامل متعدد نیازمند سازگاری مستمر هستند. چارچوب Well-Architected و اصول مرتبط راهنما ارائه میدهند. مدل مالکیت، که در آن تیمها مالک، سازنده و مستقرکننده راهکارهای خود هستند، مسئولیت را روی تیمهای اپلیکیشن میگذارد. خطای انسانی و غفلت اجتنابناپذیر است. خودکارسازی، ثبات ایجاد میکند.تست و راستیآزمایی
روشهای تست از نظر متدولوژی متفاوت هستند. ابزارهایی مثل Chaos Monkey تست واکنشی ارائه میدهند با وارد کردن خرابی به سیستمهای در حال اجرا. تحلیل حالات شکست و اثرات (FMEA) تحلیل پیشبینانه ارائه میدهد با ارزیابی نظاممند مؤلفهها برای شناسایی شکستهای بالقوه و توسعه راهبردهای کاهش ریسک. هر دو رویکرد ارزش دارند، هرچند FMEA برای تست جامع در هر لایه اپلیکیشن ترجیح داده میشود تا تحلیل و راهبرد کاهش ریسک بهطور کامل شکل بگیرد. TrueCD بهعنوان متد CI/CD شرکت توسعه داده شد؛ یک فرایند خودکار دوازدهمرحلهای با مستندسازی کامل که در پستهای وبلاگ منتشر شده است. این فرایند شبیه چکهای ایمنی پیش از پرواز در صنعت هوانوردی عمل میکند.لایه انتزاع
انتقال از درونسازمانی به ابر روی معماری اپلیکیشن اثر میگذارد. اپلیکیشنها منطق کسبوکار قابل توجهی دارند و تغییرات پیوسته اثراتی ایجاد میکند که میتواند عملیات کسبوکار را تحت تأثیر قرار دهد. لایههای انتزاع این اثرات را کم میکنند. این رویکرد معماری از مؤلفههای best-in-class در یک ابر، چند ابر، زیرساخت درونسازمانی یا ترکیبهای هیبریدی استفاده میکند. Dapr یک چارچوب متنباز معتبر است که معماریهای چندابری را پشتیبانی میکند.جابجایی ترافیک مشتری
مهاجرت اپلیکیشنهای بزرگ را نمیتوان یکشبه کامل کرد. ابتدا میتوان سیستمها را با جمعیت کاربران داخلی اعتبارسنجی کرد تا اپلیکیشنها پایدار شوند. زمانبندیهای فشرده اغلب مشکلساز است، چون برخی مسائل و الگوهای استفاده برای کشف به دورههای مشاهده طولانیتری نیاز دارند. اپلیکیشنها باید زمان عملیاتی کافی برای بهینهسازی داشته باشند. با سبدهای گسترده کارکردها، ممکن است تکمیل همه قابلیتها در بازههای زمانی موجود ممکن نباشد. بخشبندی سیستمها به مجموعههای مجزای اپلیکیشن این چالش را حل میکند. در طول فازهای مهاجرت، جمعیت مشتریان میتواند بهصورت تدریجی و با درصدهای کوچک منتقل شود تا در نهایت مهاجرت کامل محقق شود.نتایج
پیادهسازی این راهبردها نتایج قابل اندازهگیری به همراه داشت، چون کاهش هزینههای قابل توجهی حاصل شد. شاخصهای عملکرد بهصورت چشمگیر بهتر شدند و پلتفرم در تحلیلهای مقایسهای رتبههای بالا به دست آورد. گزارشهای عمومی Dynatrace که بانکهای آمریکا را مقایسه میکنند نتیجه میگیرند سایتهایی که عملکرد زیر یک ثانیه دارند، نمایانگر عملکرد بهینه هستند.جمعبندی
از این راهبردها چند نکته کلیدی بیرون میآید. مصالحهها اجتنابناپذیرند. اثرات هزینه و عملکرد باید بدون قربانی کردن نیازهای دیگر بررسی شود. برای مثال، در معماریهای چندمنطقهای، تصمیمهای تکثیر کش نیازمند بررسی است؛ اینکه کشها فقط در یک منطقه باشند یا در چند منطقه. پیچیدگی عملیاتی افزایش مییابد، چون معماریهای ابری از مؤلفههای زیادی استفاده میکنند. کاهش این پیچیدگی و کم کردن تلاش دستی در پایش اپلیکیشن ضروری است. خودکارسازی مکانیزم کلیدی این کاهش است. مهار شعاع انفجار همچنان حیاتی است. سایتها دچار مشکل میشوند و مؤلفهها از کار میافتند. وقتی شکست رخ میدهد، دامنه اثر مهم است: آیا همه مشتریان آسیب میبینند یا فقط یک زیرمجموعه کوچک؟ این تمرکز مهم است. تضمین مشاهدهپذیری اقداممحور که به اقدامهای خودکار گره خورده حیاتی است. تمرکز روی مشتری باید محرک همه تصمیمها باشد. عملیات کسبوکار برای مشتریان است. تجربه بوق آزاد را در نظر بگیرید: وقتی گوشی را برمیدارید، انتظار دارید فوراً بوق آزاد را بشنوید. همین اصل برای اپلیکیشنها هم صدق میکند. وقتی کاربران اپ موبایل را باز میکنند، انتظار دارند فوراً نتیجه ببینند. اصل بنیادین: هوشمندانه مقیاس بده، قابل اعتماد بمان. وقتی موج بعدی ترافیک، که اجتنابناپذیر است، رخ دهد، ضعفهای سیستم آشکار میشود. هدف این راهبردها مستقیم است: هنگام جهش ترافیک، مؤلفههای حیاتی باید عملیاتی بمانند، سیستمهای اصلی باید پاسخگو بمانند و مشتریان همچنان پاسخ فوریِ مورد انتظار را دریافت کنند. کلمه کلیدی سئو: مقیاسدهی اپلیکیشنهای ابری و توزیعشدهاشتراک این مقاله
پستهای مرتبط

API
آنبوردینگ توسعهدهندگان (Developers) با کالکشنهای API چگونه انجام میشود؟

برنامه نویسی
مشارکت در سرور متنباز Vonage MCP Tooling چگونه است؟
دیدگاهها (0)
برای ثبت دیدگاه لطفاً وارد شوید.
ورودهنوز دیدگاهی ثبت نشده است. اولین نفر باشید!